TUN/TAP Tunnels
This is not a tutorial about how to use the TUN/TAP driver and related tools. A very good tutorial with many useful comments is available here.
This article focuses on a very specific use case of the TUN/TAP driver: to create a tunnel with both ends on the same host and to be able to route traffic through that tunnel. The main applications of this configuration are protocol (stack) prototyping, analysis and/or testing.
Typical Use Case
The following diagram shows the typical use case of the TUN/TAP tunnels. The client and server applications (in the top) can be any typical Linux applications, for instance a web browser and a web server or an ftp client and an ftp server. The prototyping application (in the bottom) is the application that receives and processes all the traffic that passes through the TUN/TAP interfaces.
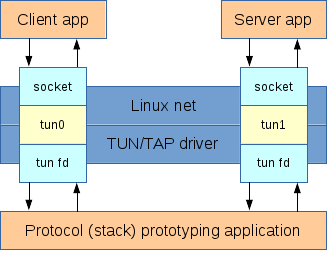
The client and server applications send and receive traffic using the traditional unix socket interface. Traffic is routed through the TUN/TAP interfaces, which appear as regular network interfaces to the Linux networking stack. However, the TUN/TAP interfaces are backed by file descriptors. These file descriptors are the interface that the prototyping application is using to receive and send the traffic from/to the TUN/TAP interfaces. This application acts as the MAC+PHY layers for the TUN/TAP interfaces.
Depending on the application, either TUN or TAP interfaces can be used:
- TUN interfaces appear as IP-only interfaces: point-to-point interfaces that have no MAC layer. In this case, no ARP is necessary because no Ethernet header is generated and raw IP packets are sent directly to the interface. The prototyping application receives/sends raw IP packets.
- TAP interfaces appear as normal Ethernet interfaces with a MAC layer. In this case, ARP is necessary because an Ethernet header needs to be generated with the appropriate destination MAC address. The prototyping application receives raw Ethernet frames.
TAP interfaces are useful for applications where Layer 2 visibility between hosts is required. But for the typical use case described above, TUN interfaces are better suited because they eliminate the complexity of the MAC layer. Therefore, the rest of the article focuses on TUN interfaces.
Problem Definition
Let's say that tun0 is configured with IP address 192.168.13.1 and tun1 is configured with IP address 192.168.13.2. Because they are point-to-point interfaces, we'll configure them by also specifying the IP address of the peer interface. This will automatically add a route to the peer IP address through the local interface.
ifconfig tun0 192.168.13.1 pointopoint 192.168.13.2
ifconfig tun1 192.168.13.2 pointopoint 192.168.13.1
We want to run the server application on 192.168.13.2 and connect to it with the client application, using an unbound socket. By default, the source IP address for unbound client sockets is the IP address of the outgoing network interface (in case it has multiple addresses, routing determines which one is used).
The problem is that normally all traffic that originates from the local host and is addressed to a local IP address is routed through the loopback interface (lo), regardless of what interface the destination IP address belongs to. That means the traffic will not flow (by default) through the TUN/TAP as we expect.
This can be tested using a sample application. It follows the typical use case described above and, for each packet that traverses the application, it prints the packet length in bytes and the incoming file descriptor. If we ping 192.168.13.2, we'll notice that we receive replies but the test application doesn't print anything. This means that the packets don't go through the TUN interfaces. By using tcpdump -nn -i lo we can easily confirm that they are going through the loopback interface instead.
Advanced Routing Configuration
In order to overcome the problems described above, some advanced Linux routing configuration is required. This section gives a brief description of the necessary routing concepts and the required configuration to make routing work as needed.
Multiple Routing Tables
Most common routing configuration tasks on Linux deal with a single routing table (like most routers do), but in fact Linux has multiple routing tables. When a route lookup is made by the Linux kernel, the route lookup does not begin in the routing table, but in the rule table. These rules are similar to some extent with iptables (because they match the packet by some configurable criteria) but decide which routing table to look up for a matching route. Like iptables, these rules are ordered and matched sequentially. The first rule that matches determines the routing table to use. If no matching route is found in the corresponding routing table, route lookup continues with the next rule.
To manipulate these rules (and also to configure advanced parameters for routes), we'll use the iproute2 package, which provides the "Swiss Army Knife" tool called ip. The legacy route Linux command provides no support for rule management and only limited support for route management.
# ip rule ls
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
Each rule has a corresponding number and rules are matched in increasing order of their number.
By default, Linux has 3 routing tables. Each table is identified by a unique number, but also a name can be assigned by configuring it in /etc/iproute2/rt_tables. The 3 default routing tables are:
- local - contains local and broadcast routes, i.e. routes to the IP addresses assigned to interfaces and to the broadcast IP addresses;
- main - these are "regular" routes and correspond to the legacy routing table in Linux;
- default - this table is empty.
Local Routing
We have already seen that all locally originated traffic to the IP address of tun1 (or tun0, for that matter) goes through the lo interface. However, this is neither magic, nor some hard-coded decision in the Linux kernel. It happens because when an IP address is configured on an interface, by default a corresponding route is added to the local routing table. If we examine it with ip route ls table local, we can observe the routes for tun0 and tun1:
local 192.168.13.1 dev tun0 proto kernel scope host src 192.168.13.1
local 192.168.13.2 dev tun1 proto kernel scope host src 192.168.13.2
These routes can be easily removed like this:
ip route del 192.168.13.1 table local
ip route del 192.168.13.2 table local
Now half of the problem is solved. The next routes that are matched are the implicit routes created by the pointopoint attribute that we used when we configured the IP addresses. This attribute creates an implicit route to the point-to-point address (the IP address of the "peer" interface) through the local interface. These routes live in the main table, which is the default for the ip route command and also the table used by the legacy route command. We can view these routes by using the ip route ls command:
192.168.13.1 dev tun1 proto kernel scope link src 192.168.13.2
192.168.13.2 dev tun0 proto kernel scope link src 192.168.13.1
At this point we can try to ping the IP address of tun1, e.g. by using ping -c 1 -W 1 192.168.13.2. We'll notice three things:
- The prototyping application receives the packet going through tun0 and delivers it to tun1. Note: the packet will appear as outgoing (egress) for tun0 and incoming (ingress) for tun1. The debug message coming from the prototyping application is this:
read 84 from fd 3. - If we use tcpdump on tun1 (e.g.
tcpdump -nn -i tun1), we can see the packet as being received by tun1:IP 192.168.13.1 > 192.168.13.2: ICMP echo request, id 18793, seq 1, length 64. - However, the ping doesn't receive any reply and fails:
1 packets transmitted, 0 received, 100% packet loss, time 0ms.
Ingress Packet Processing
So what's wrong with our current configuration? The problem is that our packets pop out of tun1 (on tun1 ingress), but the kernel does not recognize them as being addressed to the local host. If we examine the Netfilter packet flow diagram, we'll notice there is a "routing decision" on the input path. This routing decision tells the kernel what to do with the packet that just arrived.
{kind=link}
In order to determine if a packet is addressed to the local host, the kernel does not look at the IP addresses that are configured on the interfaces, as most people would expect. What it does instead is use the "routing decision" on the input path. This is a very clever (but not so obvious) optimization. A routing decision on the input path is needed anyway: for a Linux box that acts (mainly) as a router, the routing decision is needed to determine where (to what interface) the packet needs to go. This is standard routing theory. Now the clever part is that the same routing decision is used in order to determine if the packet is addressed to the local host: the condition is to match a local type route, where both the interface and the IP address match.
Wait a minute! The routes that we need in order to accept the packets and process them as addressed to the local host are the routes that we previously deleted. It turns out that these local type routes actually serve two purposes:
- On the output path, they make the packets go through the
lointerface. - On the input path, they make the packets be treated as addressed to the local host and processed as such.
Splitting Input and Output Routing
Luckily, the output and input routing decisions are different. Of course they are. What I mean is that they are triggered from different parts of the network stack code, with different "parameters". This is also suggested by the Netfilter packet flow diagram, where the two routing decisions are illustrated by distinct blocks (one on the input path and one on the output path).
The solution to our problem is to take advantage of the distinct routing decisions and configure routing in such a way that the local type routes are only "seen" by the input routing decision. The key here is to use a rule that matches the input interface: the iif parameter to the ip rule command. The rule will match only during the input routing decision, where the "input interface" attribute of the packet is set to the interface that received it (tun1 in our example). During the output routing decision, the "input interface" attribute of the packet is not set and will not match the rule (actually, in the kernel code, interface "indexes" are used for this attribute and, during the output routing decision, the attribute is set to 0 - which doesn't correspond to any interface, since valid interface indexes start at 1).
The commands for accepting incoming traffic on tun0 are:
ip route add local 192.168.13.1 dev tun0 table 13
ip rule add iif tun0 lookup 13
The commands for accepting incoming traffic on tun1 are:
ip route add local 192.168.13.2 dev tun1 table 13
ip rule add iif tun1 lookup 13
Note that for accepting incoming packets on tun1, only the 2nd set of commands is necessary. However, this is still not enough for the ping to work, because this only solves the problem of the ICMP echo request (going from 192.168.13.1 to 192.168.13.2). This packet will be accepted and the IP layer will generate a corresponding ICMP echo reply, from 192.168.13.2 to 192.168.13.1. The reply packet will have the same problem when it's received by tun0.
This can be tested by adding first (only) the route and rule for tun1. Then the following behaviour will be observed.
tcpdump shows both packets (request and reply):
IP 192.168.13.1 > 192.168.13.2: ICMP echo request, id 19377, seq 1, length 64
IP 192.168.13.2 > 192.168.13.1: ICMP echo reply, id 19377, seq 1, length 64
The prototyping application transports both packets:
read 84 from fd 3
read 84 from fd 4
But the ping still doesn't work until the route and rule for tun0 are added.
Of course, ping is just a simple test. But in the configuration described above, all kinds of traffic works. The configuration has been successfully tested with http and ftp.